いま改めて「文字コード」について(その3)
2021/09/02

今回は「文字コード」についての最終回です。UnicodeR の続きとして文字符号化方式を中心に話させていただきます。
Contents
代表的な文字コード(その3)
(9)文字符号化方式 [UTF-32、UTF-16、UTF-8]
文字コードにおいて、定義する対象の文字の集まりを「文字集合」、その各文字に番号付けしたものを「符号化文字集合 (coded character set)」といいます。また、符号化文字集合を実際に通信や保存などするためにデータ化する方法を「文 字符号化方式(CES:Caracter Encoding Scheme)」[※20]といいます。ASCII文字や JISコードの区点コードは符号化文字集 合に該当します。ASCIIコード や シフトJIS、EUC では、符号化文字集合(漢字部分は区点コード)と文字符号化方式が一体 となって定義されています。
これに対して「UnicodeR/ISO 10646」ではそれぞれ独立した定義がされており、文字符号化方式には次のものがあります。

(a)バイト順について
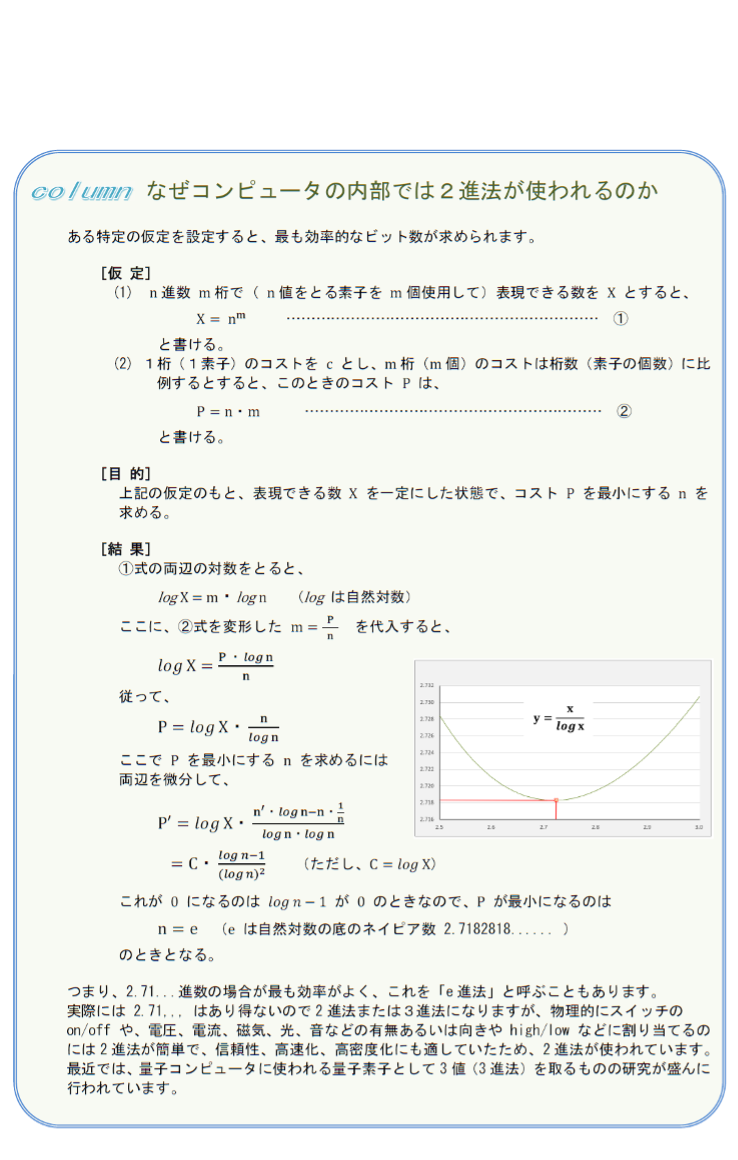
通信やコンピュータの内部では8ビット(1バイト)単位にデータを扱う場合が多くありますが、9ビット以上(通常は16ビットや32ビット、64ビット)のデータをバイト単位に送ったり保存したりする場合に、上位バイトから行うか下位バイトから行うかをバイト順(バイトオーダ、Byte order または エンディアン、Endian)といい、上位バイトからの場合を「BE(ビッグエンディアン/Big-endian)」、下位バイトからの場合を「LE(リトルエンディアン/Little-endian)」[※21] といいます。データ列を見てバイト順を判断できるようにするためにデータ列の先頭に置かれるデータを「BOM(Byte Order Mark:バイト順マーク)」[※22] と呼び、32ビット(UTF-32[※23])では「0x00 0x00 0xfe 0xff」、16ビット(UTF-16)では「0xfe 0xFF」、8ビット(UTF-8)では「0xEF 0xbb 0xbf」が使われます。

(b)UTF-32
BOM付きの場合を「UTF-32」、BOMなしで Big-endian の場合を「UTF-32BE」、BOMなしで Little-endian の場合を「UTF-32LE」と呼びます。
UTF-32 では、符合位置である 0x0~0x10ffff(21ビット)をそのまま 32ビット のコードとして符号化します。すべての文字が32ビット(4バイト)の固定長になります。


(c)UTF-16
BOM付きの場合を「UTF-16」、BOMなしで Big-endian の場合を「UTF-16BE」、BOMなしで Little-endian の場合を「UTF-16LE」 と呼びます。
UTF-16 では、1文字を 16ビット を単位とする 16ビット または 32ビット のデータで符号化します。第0面の基本多言語面 (BMP)内の文字(U+000000~U+00FFFF)は、そのまま下位16ビット分が文字コードとなります。ただし U+00D800~U+00DFFF の領域は文字が定義されておらず、この部分を利用して第1面以降(U+010000~U+10FFFF)を符号化します。0xd800~0xdbff と 0xdc00~0xdfff の各16ビットを上位16ビット、下位16ビットとして、全体で32ビットとして文字コードを作ります。この 16ビットの組を「サロゲートペア(代用対;surrogate pairs)」といいます。(詳細については、下表を参照してください。)

つまり、第0面(BMP)の文字は16ビット、第1面以降の文字は32ビットで符号化されます。


(d)UTF-8
UTF-8 の場合、データは8ビット単位で作られるため、バイト順の指定はありません。通常はBOMなしが使われ(推奨され)、単に「UTF-8」、または、明示的に「UTF-8N」[※24] と呼ばれます。BOM付[※23] の場合でも常に Big-endian となり、先頭に「0xef 0xbb 0xbf」が付加されます。
UTF-8 では、1文字を1バイトから4バイトで符号化します。U+000000~U+00007F の基本ラテン文字ブロックは、符合位置の最下位1バイトがそのまま1バイトの文字コードとなります。つまり、ASCII文字はそのまま符号化されます。続く U+000080~U+0007FF の領域は2バイト、U+000800~U+00FFFF の領域は3バイト、最後の U+010000~U+10FFFF の領域は4バイトで、それぞれ符号化されます。


ASCII文字は1バイト(コードも同じ)、ウムラウト付きのアルファベットなどのヨーロッパ系文字とシリア文字、アラビア文字などは2バイト、アジア・アフリカ系文字や先住民文字などは3バイト、第1面以降は4バイトで符号化されます。UTF-16 と比較すると、ASCII文字は1バイトで済み ASCIIコード と互換性がありますが、その他ヨーロッパ系文字は2バイト、CJK統合漢字や平仮名、片仮名を含むアジア・アフリカ系文字などは3バイトとなり、符号化長が長くなります。
(e)その他の文字符号化方式
UnicodeⓇ/ISO 10646O 関連では他に UTF-7、UCS-2、UCS-4 などがあり、シフトJIS、EUC-JP、ISO-2022-JP なども文字符号化方式といえますが、本稿では省略させていただきます。
TIPs
Windows 10 を中心に、いくつかの TIPs を紹介します。
(1) Internet Explorer で文字化けする場合[※25]
Internet Explorer で開いたページが文字化けする場合、
[表示(V)] – [エンコード(D)]
または、
右クリックのメニューから [エンコード(E)]
で文字コードを変更することができます。これで可能性のある文字コードを選択してみてください。
Microsoft Edge には、この機能はないようです。
Google Chrome では、拡張機能をインストールする必要があります。
Mozilla の Firefox Browser では、[表示(V)] – [テキストエンコーディング(C)] で同様の機能が利用できます。
(2) Internet Explorer で文字コード(符号化)を判別する
上記(1)で文字コードを指定する際にすでに選択されている文字コードが、各ブラウザが認識した文字コードです。文字化けなく表示されている場合は、正しく認識していると考えられます。
なお、それぞれのブラウザでテキストファイルを開くには、テキストファイルをブラウザ上にドラッグ&ドロップするか、
IE [ファイル(F)] – [開く(O)… Ctrl+O] で右下の [参照(R)…] をクリックし、右下の
ファイル種別で [テキストファイル] を選んでファイルを選択します
Firefox 右上の(メニューを開きます)から(ファイルを開く… Ctrl+O) または
[ファイル(F)] – [ファイルを開く(O)… Ctrl+O] からファイルを選択します
とします。
(3) メモ帳で保存するファイルの文字コードを指定する
メモ帳でテキストファイルを開くか作成します。このとき、使われている文字コードが右下に表示されます。
ファイルを保存するときに、[ファイル(F)] – [名前を付けて保存(A)… Ctrl+Shift+S] として、中央下にある(文字コード(E):)で保存する際の文字コードを指定できます。
選択できる文字コードおよび符号化方式は下記のものです。
ANSI : シフトJIS (Microsoftコードページ932/CP932)
UTF-16LE : Unicode UTF-16 Little-endian (BOM付き)
UTF-16BE : Unicode UTF-16 Big-endian (BOM付き)
UTF-8 : Unicode UTF-8 (BOMなし) ———– 推奨
UTF-8(BOM 付き) : Unicode UTF-8 (BOM付き)
なお、Windows 7 や Windows 8 では、➀ ANSI:シフトJIS ② Unicode:UTF-16LE(BOM付き) ③ Unicode big endian:UTF-16BE(BOM付き) ④ UTF-8:UTF-8(BOM付き)、となっています。
(4) UnicodeⓇ の符合位置で文字を入力する
Microsoft IME の「IME パッド(P)」を開き、左側のバーの上から2番目の「文字一覧」を開きます。開いたポップアップの上中央のフォント指定は「Meiryo UI」または「游ゴシック」にしておきます。UnicodeⓇ であれば左側のウィンドウが面とブロックの指定になります。例えば [Unicode(基本多言語面)] の [CJK統合漢字](2/3 位のところにあります)を選ぶと、中央のウィンドウに漢字の一覧が表示されます。行の(U+xxxx)と列の最下位1桁(4ビット)の組み合わせが符合位置になります。例えば「串」は(U+4E30)行の(2)列で、符合位置は「U+4E32」になります。
(5) Microsoft IME で異体字を入力する
上記(4)同様にIMEパッドの一番上「手書き」を開き、文字を書いて中央の漢字のウィンドウに候補を表示させます。対象の漢字を右クリックして [異体字の挿入] で表示される文字(グリフ)から選択します。
おわりに
日本産業規格(JIS)では、独自の文字コードによる規格化を終了し、「JIS X 0221 国際符号化文字集合(UCS)」(ISO/IEC 10646、UnicodeⓇ の翻訳規格で、内容は大部分が一致しています)に統合していく方針です。普段使用する環境でも「UnicodeⓇ/ISO 10646」が使われる場合が多くなり、普通の文章を書くには文字コードを気にする必要はなくなっています。ただし、紙文書と違い、デジタルデータは環境によって表示/印刷される文字の形が違ってしまう場合があります。人事・総務系の業務では、人名や会社名、地名などの固有名詞を扱う場合もあり、文字の種類、特に異体字には注意が必要です。何か問題が起こった場合は、一度、文字コードのことを思い出してみてください。
------------------------------------------------------------------------------
※20 単に「符号化方式」と書く場合があります。本来は「符号化形式(encoding form)」と「符号化方式
(encoding scheme)」は分けて定義されていますが、ここでは厳密には分けずに書きます。
※21 「Big-endian/Little-endian」は、スウィフトのガリバー旅行記の小さな人達の国であるリリパット国
とブレフスキュ国の国民の呼び名からきているそうです。(ゆで卵の殻を正しく割る方向が由来)
※22 UnicodeⓇ では BOM ですが、ISO 10646 では「ZERO WIDTH NO-BREAK SPACE(ZWNBSP)」と呼ばれます。
※23 「UTF」は、UnicodeⓇ では「Unicode Transformation Format」、ISO 10646 では「UCS Transformation
Format」の略です。
※24 BOM付の UTF-8 は国際的にみると一般的ではなく、主に日本国内で使われます。従って、BOMの有無を
区別するための「UTF-8N」という呼称も、主に国内で使われます。
※25 HTMLタグの “charset=” を直接書き替えたり、挿入する方法もあります。



