いま改めて「文字コード」について(その1)
2021/05/11

Contents
【はじめに】
最近では Unicode® が使われることが多くなり、ほとんどの場合文字コードは自動認識されたり自動変換されるため、文字コードそれ自体が何であるかを意識することは少なくなっていると思います。それでも、Windows/Mac/Unix の間や古いバージョンのOSでは、文字化けすることもあります。本稿では、改めて「文字コード」について整理してみたいと思います。
多少技術よりの内容も含まれて長くなっていますので、詳細が必要のない方は読み飛ばして、どんな種類の文字コードがあるかの紹介として、技術系の方にとっては詳細が書かれているわけではありませんので、これまでの知識の整理や文字コードにの関する入門用として利用いただければ幸いです。
第1回は、文字コード全般と ASCIIコード、JISローマ字カナコード、旧JISコードについて説明していきます。
【文字コードとは】
ご存知のとおり、コンピュータの内部は2進数(2進法)でデータを表現し、計算しています。文字を扱う場合にも、それぞれの文字を2進数に対応させる必要があり、この対応を文字コード(character code)といいます。ただし、ここでいう文字とは、(正確な表現ではありませんが)「ある文字の概念を指す」もので、実際に画面に表示されたり、プリンタで印刷されたりするものとは異なります。同じ文字で形が異なるだけと考えられるものを異体字といいますが、例えば は異体字とされ、同じ文字コードが振られています。[※1] この例のように、文字の形を表すものをグリフ(glyph)といいます。我々が実際に目にする文字は、このグリフに、さらにフォントの種類・サイズ・太さなどを指定してデザイン性や大きさを加味して表示/印刷されたものになります。
は異体字とされ、同じ文字コードが振られています。[※1] この例のように、文字の形を表すものをグリフ(glyph)といいます。我々が実際に目にする文字は、このグリフに、さらにフォントの種類・サイズ・太さなどを指定してデザイン性や大きさを加味して表示/印刷されたものになります。
コンピュータが外部と接続されていなければ内部の処理にどのような文字コードを使っていても問題は起きませんが、USBメモリのような外部媒体やネットワークを通して他のコンピュータと接続されると、そのコンピュータ間で同じ文字コードを使っていないと文字が正しく表示されなくなってしまいます。この意味で、データ交換には文字コードの統一、規格化が重要になります。そのため、国際的には ISO(International Organization for Standardization;国際標準化機構)および ISO/IEC(International Electrotechnical Commission;国際電気標準会議)の合同委員会、国内では JIS(Japanese Industrial Standards;日本産業規格)などで文字コードの標準化・規格化が行われています。
【16進表記について】
ここでは本論から外れますが、具体的な文字コードをご紹介する前に、文字コードの表記に必要となる16進表記について整理しておきましょう。
皆さんが普段使っている10進数(10進法)は、10種類の数字を使って表現され、9を超えて桁上りがあると2桁になって「10」と書かれます。コンピュータの内部では2進数(2進法)が使われており、同じように2種類の数字(通常は「0」と「1」を使います)を使い、1を超えて桁上りがあると「10」と書かれます。ただ、この方法では、例えば10進数の「418」は「110100010」となり、桁数が多くてわかり難く、取り扱いも不便です。そこで、2進数を4桁ずつに区切り、4桁分を16種類の数字を使って表記する16進表記を用いて表します。その数字が16進数、処理方法が16進法です。この4桁というのは2の累乗(22)桁数となるので、2進数との親和性も良くなります。11番目以降の数字には、通常「A」~「F」が使われ、前述の10進数「418」は「1A2」となります。16進数の表記方法には、「1A2」「1a2」「0x1a2」「0x1A2」「1A2H」「X’1A2’」「1A216 」などいろいろありますが、本稿では混乱を招かない場合は単に「1A2」と書き、16進表記であることを明示する場合は「0x1a2」と書くことにします。
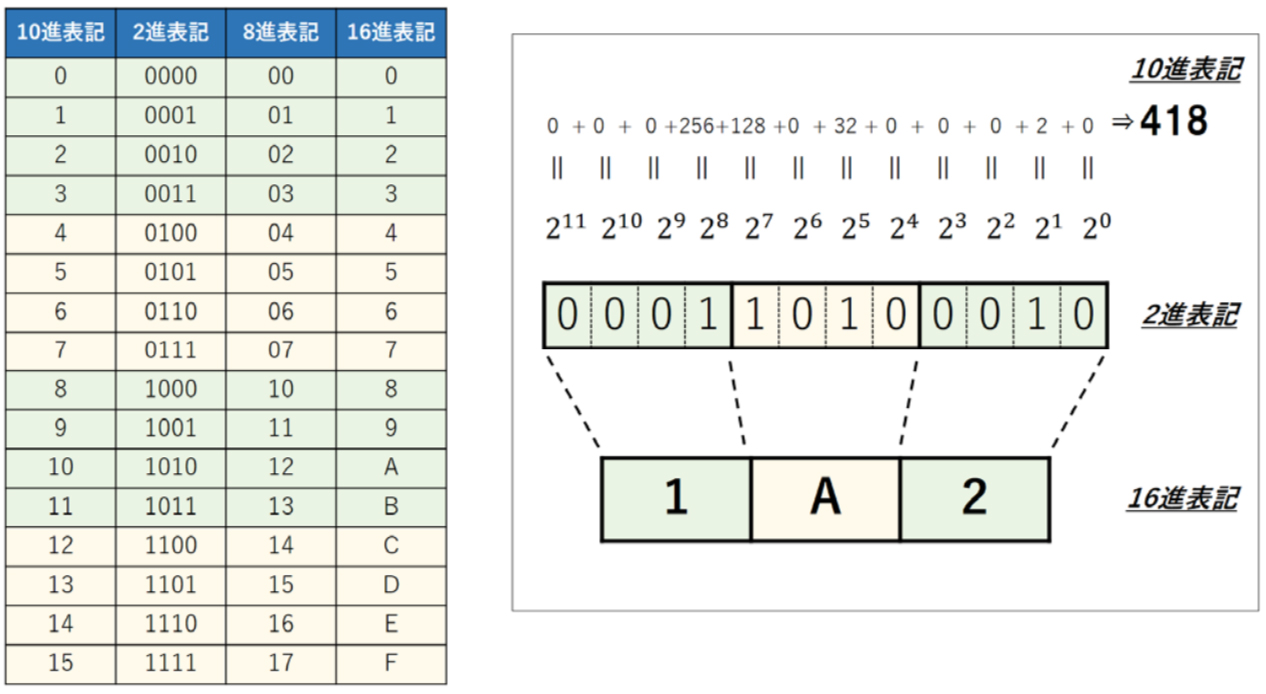
また、ご存知のとおり、2進数1桁を「ビット(bit)」、8ビットを「バイト(byte)」と呼びます。これを16進数で表現すると、「1バイト(8ビット)は 16進数2桁、16ビットは 16進数4桁、32ビットは 16進数8桁」ということができますし、また、「16進数1桁は 4ビット」になります。
【代表的な文字コード(その1)】
この項では、代表的な標準・規格による文字コードについてご紹介していきます。
(1)ASCIIコード
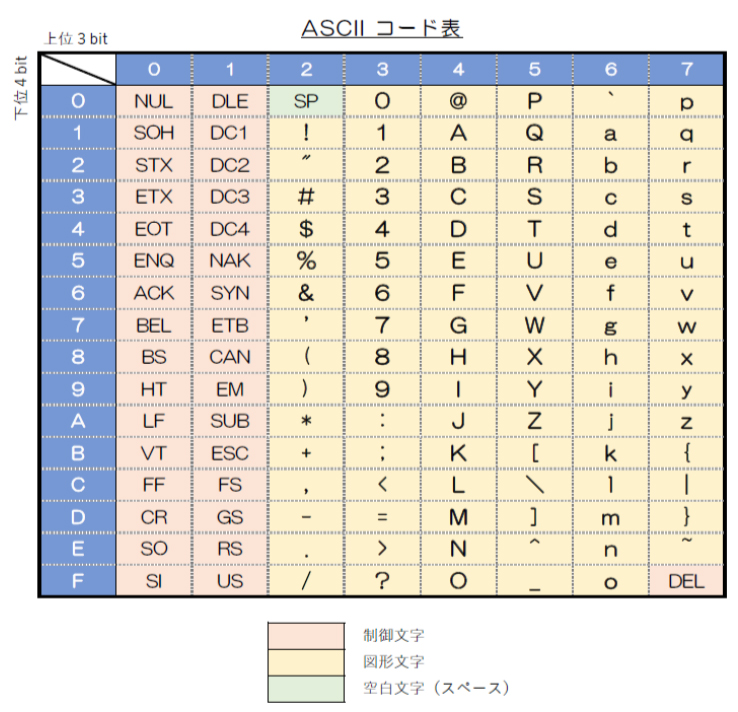
1960年頃から、米国を中心に文字コードの標準化が始まりました。当時は機種毎にばらばらな文字コードが使用されており、ビット数も4~6ビットと統一されておらず、60種類程度のコードが存在したといわれています。コンピュータに関してトップ企業であったIBM(International Business Machines Corporation)内でも、9種類の方言が使用されていたそうです。その当時、初めて規格化された文字コードは、ANSI(American National Standards Institute;米国国家規格協会)で制定された「ASCIIコード」[※2](American Standard Code for Information Interchange;アスキーコード)です。当初の規格番号は「ASA X3.4-1963」でしたが、ASA が ANSI に改組されたり規格の改定があったりして規格番号が「ANSI INCITS 4-1963」(旧ASCII)、「ANSI X3.4-1986」「ANSI INCITS 4-1986」(US-ASCII)と変わり、最新の正式名称は「ANSI INCITS 4-1986[R2017]: Information Systems – Coded Character Sets – 7-Bit American National Standard Code for Information Interchange (7-Bit ASCII)」となっています。1963年の最初の規格では7ビットコードの他に6ビットコードも規定されていたり、英小文字は規定されていなかったり、後述の制御文字の規定が現在と異なったりしていましたが、1986年版の俗称「US-ASCII」でほぼ現在の内容になっています。ここでは、この7ビットコードである「US-ASCII」について説明します。
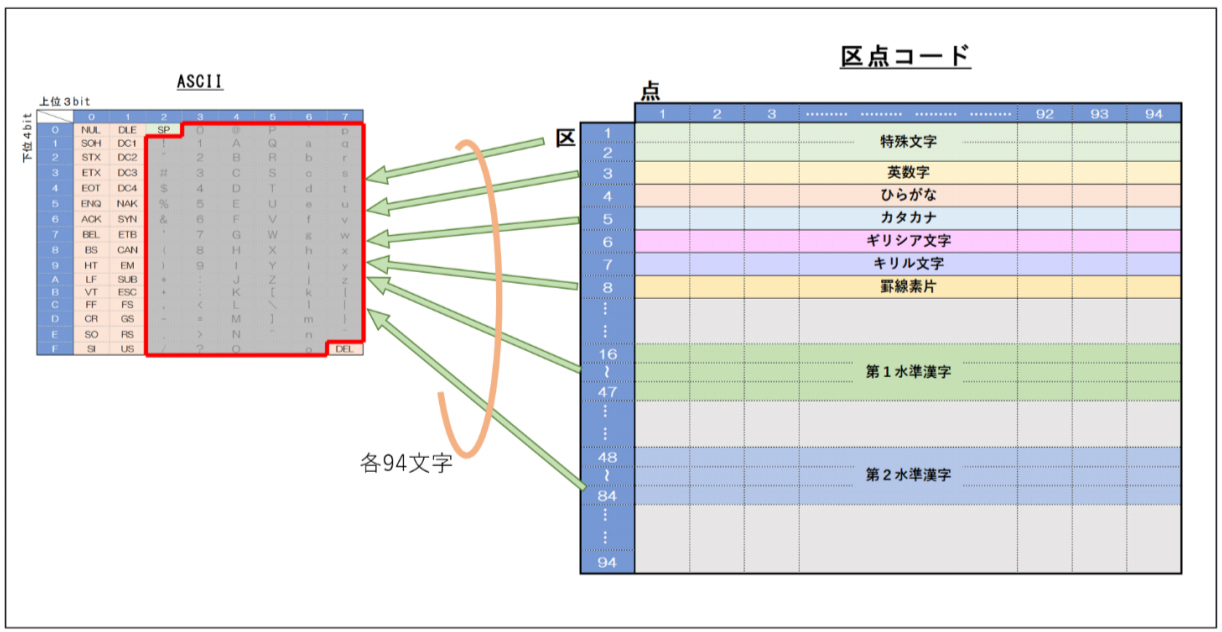
ASCIIコードは2進数7桁(7ビット、0x00~0x7f)の128文字で構成されます。エリア毎に定義される機能は、下表のように分かれています。

コンピュータ内部の処理負担を減らすために文字数を制限して7ビットとしていますが、規格制定当時でも、実際のデータは8ビット単位に交換/通信されていました。そこで、最上位桁の8ビット目は、チェックビット(パリティビット)として使われる場合が多く、その名残で、現在でも7ビットしか使えない環境が残っています。
この ASCIIコードはその後の各種文字コードの元になっており、ほとんどの文字コードで 0x00~0x7f の範囲は ASCIIコードと互換性を保っています。
(2)JISローマ字カナコード(JIS X 0201、ANKコード)
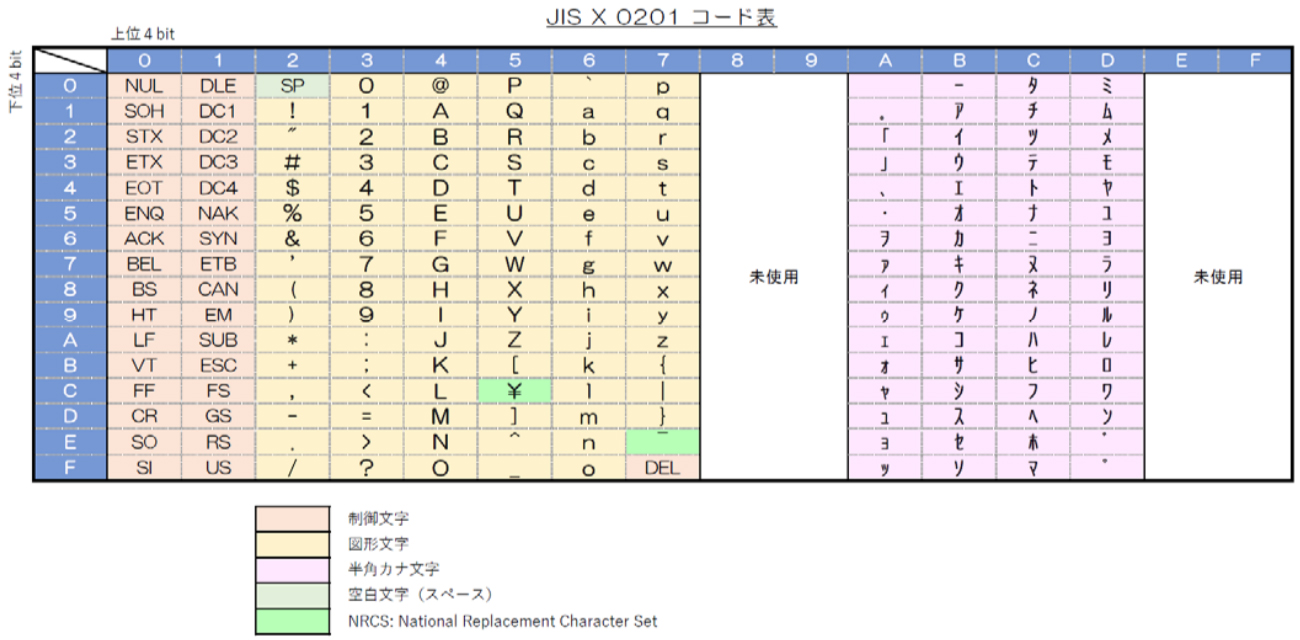
US-ASCIIコードでは米国以外の文字[※3] が表記できないため、ASCII が拡張され、さらにそこから国際規格である ISO R 646(最新版は「ISO/IEC 646:1991 – Information technology — ISO 7-bit coded character set for information interchange」)が制定されました。これは、ASCIIコードの一部を各国で定義してローカル規格の元とすることを認めたもので、日本では「\」を「\」に、「~」を「 ̄」に入れ替え、さらに半角カナ文字を加えた8ビットコードとして「JIS C 6220」(後に「JIS X 0201」と改称されました)が制定されました。この規格は、0x00~0x7f の範囲は一部の NRCS[※4](National Replacement Character Set;国際使用文字)を除き ASCIIコードと同じ定義になっており、0xa1~0xdf に半角カナ文字[※5] が定義されています。半角カナ文字は、文字数を減らすためにカタカナだけが定義され、濁音・半濁音は独立した文字として定義された濁点(「゛」)・半濁点(「゜」)と組み合わせて使用することになっています。この文字コードは、含まれている文字の種類である Alphabet、Numerical digit、Katakana の頭文字をとって「ANKコード(ANK文字)」と呼ばれることもあります。
(3)旧JISコード(JIS C 6226-1978)
ISO 646 では、国によって NRCS の部分に違う文字が表示されてしまうことと、漢字やアラビア語などのように8ビット(256文字)では主要な文字だけでも収容しきれない言語があるため、ISO 646 をベースに、一部のコード部分の文字を明確に入れ替えて多く文字を表示でき、かつ、一つの規格で各言語を網羅できるよう、1973年に ISO 2022(最新版は、「ISO/IEC 2022:1994 – Information technology — Character code structure and extension techniques」)が制定されました。日本ではこの規格をベースに、JIS として初めての漢字コード規格である「JIS C 6226-1978」[※6](通称「旧JISコード」、「78JIS」と呼ばれることもあります)が制定されました。
「旧JISコード」では、ASCII の印字文字である 0x21~0x7e の 94文字の部分(「GL領域」と呼ばれる)を入れ替えて多くの文字を定義する方法を取っています。定義できる文字数は、他のコードと重複しないように 0x21~0x7e を2個組み合わせた8,836(94×94)文字の範囲とし、94×94 の正方形のエリアに定義されます。JIS では、上位桁の 1~94 を「区」、下位桁の 1~94 を「点」と呼び、合わせて「区点コード」と呼びます。ASCII文字と漢字の入れ替えは「エスケープシーケンス(escape sequence)」と呼ばれる「ESC文字(0x1b)」から始まるコード列が出現することで行われ、「JIS C 6226-1978」では次のように規定されています。
ASCII ⇒ JIS(漢字)の切替え : 「1B 24 40」(16進表記)、 「(ESC) $ @ 」(文字表記)
JIS(漢字)⇒ ASCII の切替え : 「1B 28 42」(16進表記)、 「(ESC) ( B 」(文字表記)
例えば、「12三井倉庫BP12」と表示したい場合は、次のようなコード列を送ることになります。
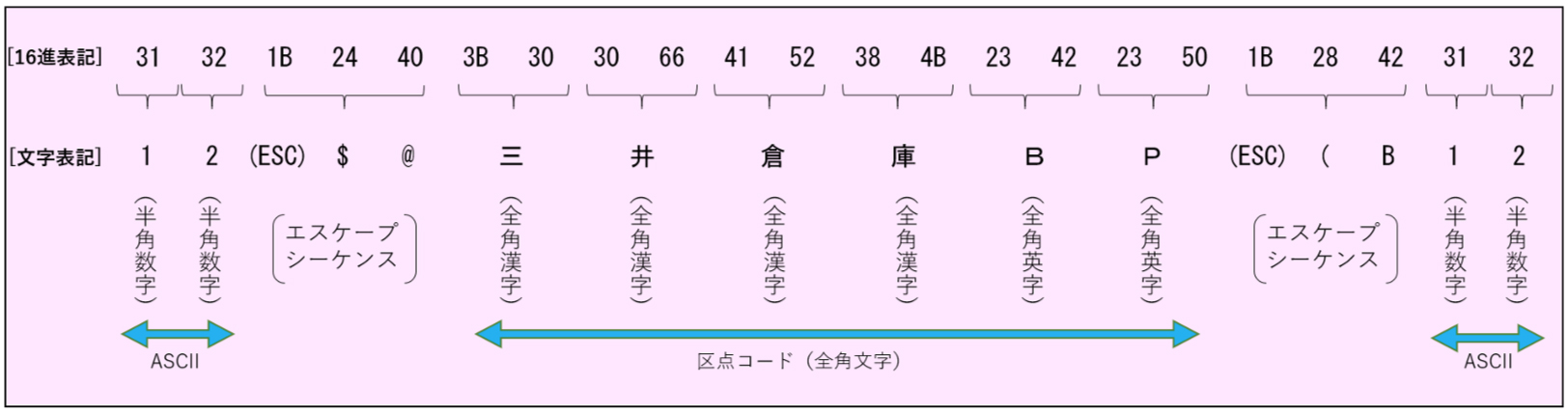
「旧JISコード」で規定されている文字は、94×94 の区点コード部分に非漢字 453字 および 漢字 6,877字、非漢字部分には全角の英数字・記号、ひらがな、カタカナ、ギリシア文字、キリル文字、罫線記号が定義されていますが、「JIS X 0201(ANKコード)」にある半角カナ文字は規定されていません。また、漢字は、使用頻度に応じて第1水準(2,965字)と第2水準(3,384字)に分けられ、第1水準は五十音順に、第2水準は康煕字典順に並べられています。第1水準は、当用漢字表などに含まれる文字の各種漢字表における出現頻度を元に選択し、人名・地名用漢字が加えられています。第2水準は、当用漢字表の残りの文字にその他の漢字表で必要と判断された文字を加えた中から選択されています。
「旧JISコード」では全てのコードが 0x00~0x7f の範囲になるので、8ビットのデータになる「JIS X 0201(ANKコード)」とは異なり、7ビットのデータしか使えない環境でも使用することができます。現在では 8ビットデータを使えない環境は少なくなっていますが、古い環境の場合は7ビットに制限される場合もあり、そのような場合にJISコードは有効です。
[以下、(その2)に続く]
※1JISコードでは 1-19-75(336b)、Unicode® では U+00845B が振られていますが、JIS の改定により と変わってきました。※2「ASCII」がコード(code)の略なので正しくは「ASCII」または「アスキー」ですが、本稿では慣例に従い「ASCIIコード」と書きます。※3例えば「â」「Ï」「Ú」「è」「Ø」「β」「Ω」「£」「§」「æ」「\」「ア」など。※4“national use positions”と呼ばれることもあり、
と変わってきました。※2「ASCII」がコード(code)の略なので正しくは「ASCII」または「アスキー」ですが、本稿では慣例に従い「ASCIIコード」と書きます。※3例えば「â」「Ï」「Ú」「è」「Ø」「β」「Ω」「£」「§」「æ」「\」「ア」など。※4“national use positions”と呼ばれることもあり、
0x21~0x24、0x26、0x3a、0x3f、0x40、0x5b~0x60、0x7b~0x7e
が対象となります。例えば、英国では 0x23 に「£」が割り当てられています。JIS X 0201 では、0x5c に「\」の代わりに「 ¥ 」が、0x7e に「 ∼ 」の代わりに「 ‾ 」が定義されています。このことから、日本語以外の Windows ではフォルダ(ディレクトリ)の区切りに「\」が表示されるのに、日本語版の Windows では「 ¥ 」が表示されます。内部的には、同じコード 0x5c が使われています。※5「半角カナ文字」といっても正式な名称ではなく、半分の幅の文字を使うという規定もありません。一般的な漢字には16ビット以上のコードが割り当てられるのに対して8ビットコードであることと、システムの都合で、固定幅のフォントで表示/印字した場合に全角の漢字の半分の幅となるため、俗称として「半角カナ文字」と呼ばれています。内部的には、全角のひらがなやカタカナとは違うコードが割り当てられます。ただし、「Unicode®」や「JIS X 0213」(例えば「JIS X 0213:2000『附属書5(規定)文字の代替名称』」)では「Halfwidth Katakana」と定義され、正式名称になりました。「半角カナ文字」を最も良く目にするのは銀行口座で、全国銀行データ通信システムに使われていたため、互換性のために口座名義などには「半角カナ文字」が使われています。最近では「半角カナ文字」が使用できないシステム(コード/プログラム)もあるので、文字化けの原因となることもあり、必要外に使用することは避けた方が好ましいと言われています。※6「1987年に JIS に情報部門(X)が新設され、規格番号が「JIS C 6226」から「JIS X 0208」に改称されました。この時すでに「JIS C 6226-1978」は廃止されていた(既に「JIS C 6226-1983」が発行されていた)ので実際には「JIS X 0208:1978」という規格は存在しませんが、俗称として「JIS X 0208:1978」と呼ばれることもあります。