AI-OCRってなに?(その1)
2021/01/28
はじめに
ここ数年、AI-OCR [*1] と呼ばれるものがもてはやされ、実際に利用が拡がってきています。特に、RPA(Robotic Process Automation)と組み合わせて使用することで、事務作業の効率化につながっているようです。今回は、AI-OCR とはどのようなものかについて、基本的な部分を中心に説明してみたいと思います。
そもそも「AI-OCR」と呼ぶくらいですから、そのままに言ってしまえば「AIを利用したOCR」ということになります。日本語文にすれば「人工知能を利用して高精度化し、認識率を向上させた文字認識システム(ソフトウェア)」といことになるでしょうか。
では、それぞれについて説明していきます。
画像データと文字データ
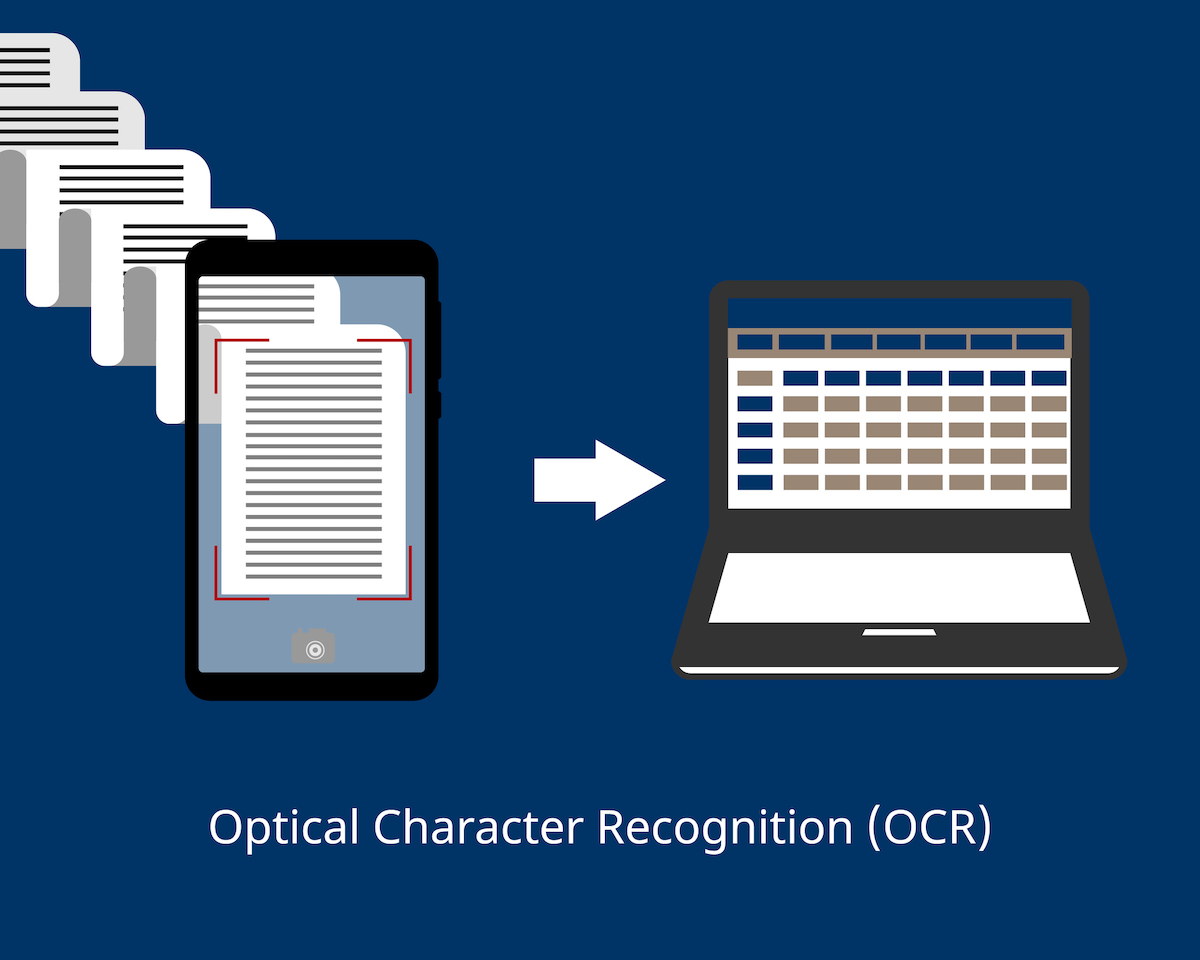
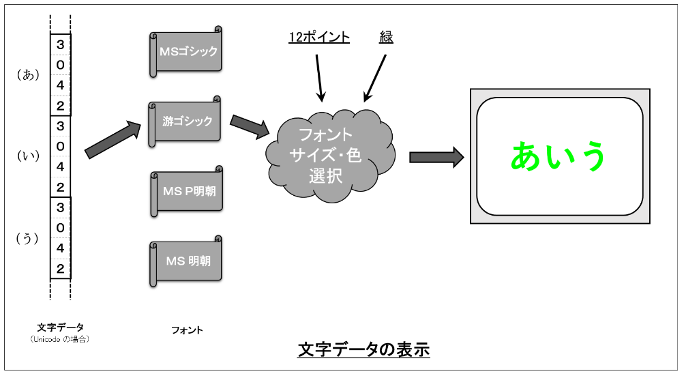
例えば Word や Excel のようなソフトウェアでは、キーボードから文字や数字を打ち込むことで画面に文字・数字が表示されます。さらに、フォントを指定することで、その文字の形や大きさ、色を変えることができます。これは、キーボードから打ち込まれた文字データ(文字コード)から対象となるフォントを指して表示することで実現されており、このとき指定する対象のフォントを切り替えることで、表示される文字の形が変わります。
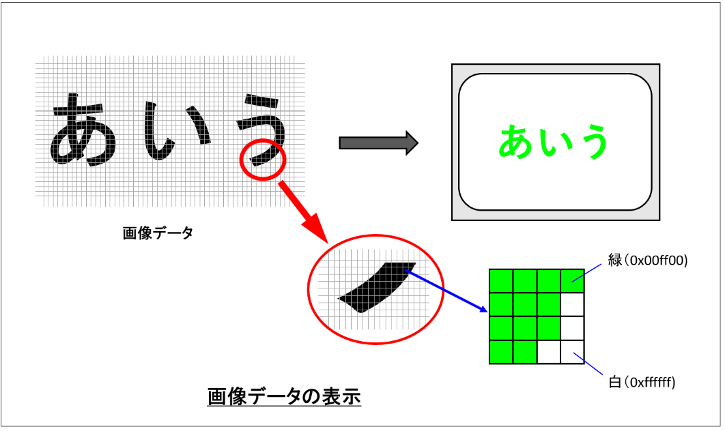
これに対して、スキャナや複合機で読み込んだ紙文書やFAXから直接取り込まれたFAX文書は、画素と呼ばれる小さく分割された区画の色を記録し、それらを集めることで目に見えるようにしています。つまり、絵(画像)としてのデータがあるだけで、そこに書かれている文字としての情報は持っていません。従って、そのまま Word や Excel に取り込んでも画像が載るだけで、修正したり検索・計算することはできません。これは、見た目は同じPDF形式のファイルでも、Acrobat で表示させたとき、文字部分を選択したり修正したりできるものとできないものがあること(他の理由で違いがでる場合もあります)にもつながっています。
住所・氏名や金額など、事務処理の対象としたいものは文字データですから、画像データだけから構成されるものは使えないことになってしまいます。このような場合、これまでは人間が画像データの表示(または紙文書)を見てデータを打ち込む「データエントリ」または「パンチ作業」と呼ばれることが行われていました。これは労働集約的な作業になるため人件費が大きなウェイトを占めており、コストダウンのために海外(中国、フィリピン、ベトナムなどが多く、”offshore” とも呼ばれます)で作業が行われることが多くなっていました。ところが、最近では個人情報の流出を防ぐために海外での作業が禁止される場合がほとんどになってきており、いかに人手を介さずに画像データを文字データに変換するかが重要になってきています。
OCRとは
(1)OCRの歴史
このように、自動的に画像データから文字データに変化する装置、または、ソフトウェアをOCR(”Optical Character Reader” または “Optical Character Recognition”)と呼びます。OCRの歴史は古く、文字がアルファベットと数字で構成される英語圏では、1928年にオーストラリアで、1929年にアメリカで特許が出願されています。ただ、欧米はタイプライター文化であったため活字文字だけを対象にするだけも良かったと思われますが、漢字文化圏である日本では手書き文書がほとんどで、日本でのOCR開発は1968年に郵便番号制度が導入されることで本格化してからになります。当初は、「はがきや封筒に印刷された赤枠の中の手書き数字」だけを対象とした郵便仕分機が開発されました。その後、活字のカナや漢字、手書きのカナに対象を拡げていきましたが、手書き漢字については実用的なものの開発は困難でした。
(2)OCR処理
OCRによる変換処理は、対象が活字だけであったとしても、活字やフォントはその種類によって形や線の太さ、「とめ・はね・はらい」や「てん」などの形が違うため、そのまま比較して変換するのは困難です。また、スキャニング時に縮小率が変わったり、傾いたり、部分的に伸び縮みが発生したりして歪むため、単純比較することがさらに困難になっています。それらがあっても変換できるように、文字の大きさを整える正規化、文字を線状に細める細線化、文字の形の特徴を抽出する特徴抽出などを行ってから比較を行います。
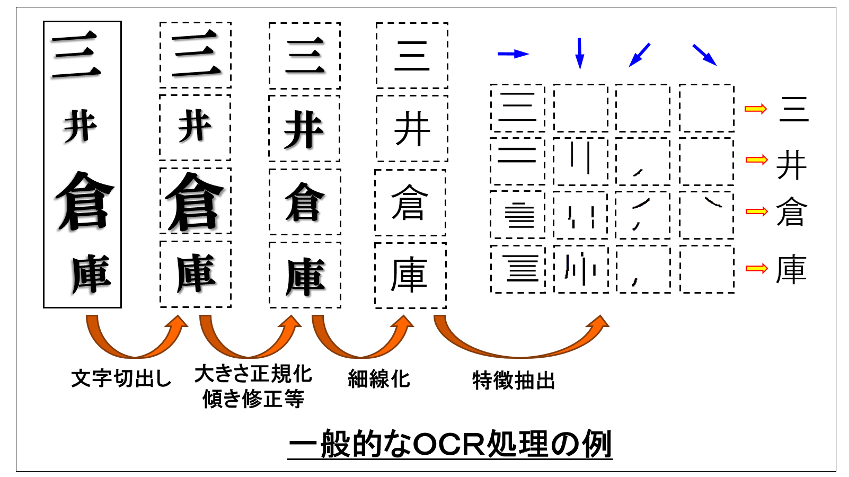
また、変換した結果が正しいか、チェックディジット [*2] の検証や、あり得る年月日や電話番号、郵便番号、会員番号か、郵便番号と地名の間に矛盾がないかなど、いろいろな論理チェックが行われる場合もあります。
(3)OCRの種類
OCRの分類についてはいろいろな考え方がありますが、ここでは、対象物による分類を紹介します。
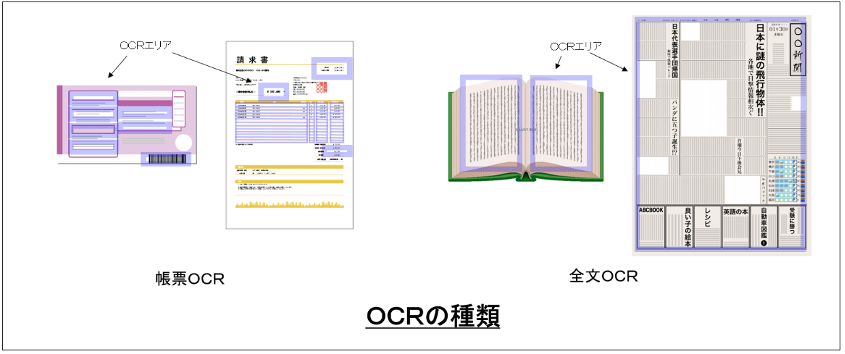
フォーマット(フォーム)が固定された特定の申請書、申込書、伝票などを対象にするものを「帳票OCR」と呼びます。帳票OCRでは、変換対象となる部分が限定され、そこに書かれている内容も決まっています。従って、対象部分の画像を切り出して、文字種(英字・数字・ひらがな・カタカナ・漢字など)や桁数を限定して変換することができます。また、前述の論理チェックもできるため、変換精度を向上させることができます。一方、変換対象の位置や内容を全て事前に定義しておく必要があり、フォーマットの変更や新規帳票への対応に工数がかかります。また、複数種類の帳票を一括して処理するためには、変換前に、自動的に帳票の種類を判断して分類する必要があります。これらの処理を「フォーム処理(フォーム・プロセッシング)」と呼び、帳票OCRでは重要な前処理になります。帳票OCRのように特定のフォーマットのものを対象とするのではなく、本や新聞、論文、袋綴じ契約書のようなもの全体を変換対象とする処理を「全文OCR」と呼びます。全文OCRでは、縦書き・横書きの判定、見出しの抜き出し、行の分割などの前処理を行い、それぞれを変換していきます。それでも帳票OCRのような精度は得られないため、キーワードの検出・検索などの範囲内で使われる場合が多くなっています。
他の分類方法では、対象の文字によって分ける「英数字OCR/日本語OCR」「活字OCR/手書きOCR」などがあります。これらの組み合わせで見れば、「活字・英数字・帳票OCR」は変換精度を向上させやすく、「手書き・日本語・全文OCR」では活用できるような変換結果を得るのは非常に困難でした。
(4)その他の処理
OCRが専用装置だった時代は、バーコードを読み取るためのバーコード・リーダ、マークシートを読み取るためのマークシート・リーダなどがありましたが、最近では、まず画像を撮り込み、ソフトウェアの処理で文字とともにマーカー、チェックボックス、QRコードを含むバーコードなどを読み取るようになってきています。スマートフォンで撮影した画像からQRコードを読み取ったり、文字を変換して翻訳したりするサービスが典型的なものです。
[以下、次回に続く]
——————————————————————————
*1 「AI 0CR」「Ai-OCR」「AI-Powered OCR」など様々な表記があるが、本稿では「AI-OCR」と書くことにする。
*2 「チェックディジット」とは、会員番号などの記入間違い、読取/変換誤りなどを防ぐために、本来の数字列(文字でもよい)に1桁(通常は1桁の数字だが、文字でも、複数桁の数字でもよい)追加して会員番号とする方法で、追加される数字の計算手順は起こりやすい誤りに適した方法に応じて多数ある。また、計算方法を非公開とすることにより、偽造防止にもつながる。住民票コード、免許証、口座番号、クレジットカード番号、伝票番号など、広く利用されている。



